I’m normally someone to stress avoiding premature optimization. Unfortunately, when deciding whether to replace Sled as the storage layer for BonsaiDb, I needed to understand whether Nebari could even remotely compare to the speed of Sled. But, I also realized I didn’t know how Sled compared to any other engine either. SQLite is one of those projects you always hear about being efficient, and rightfully so, so I wanted to compare Nebari against both of those projects.
There are many other reasons I decided to keep developing Nebari, but today, I’m going to focus on the struggle I had getting Nebari to the point that I could write that last devlog.
Initial stages of benchmarking Nebari
From the outset of working on BonsaiDb, my only goals were to scale as well as CouchDB, as I had built my last business on it. One of the simplest things I should have done much sooner was set up a CouchDB benchmark. I had no idea how performant CouchDB was compared to any other database engine – even after my extensive experience with it.
Because CouchDB isn’t as easy to set up, I started my Nebari benchmark suite only comparing against SQLite. After getting my initial suite working, I found that on single-row inserts and retrievals, I could beat SQLite, but for larger operations, SQLite would easily beat me. I don’t have good graphs, because at the time I was experimenting with Nebari being async and using supporting io_uring. This is the best image I had prior to switching to Criterion for benchmarks after ditching async:
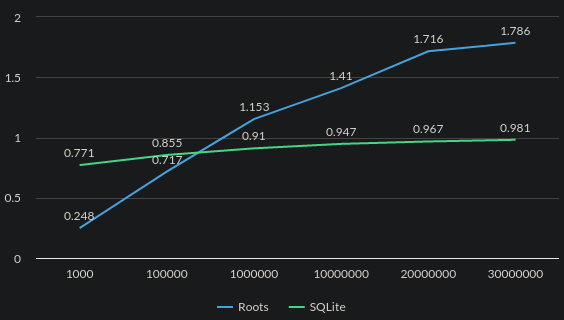
This graph is measuring how long it takes to retrieve 100 records out of a data set of varying sizes. As you can see, SQLite is steady, and while I could beat it on small datasets, I wasn’t happy with how this was turning out, though. I should have been happy enough given that the project was only 2 weeks old, but try as I might, I just wasn’t happy with these results.
I decided it was time to benchmark Sled and CouchDb after switching to Criterion.
The new benchmark suite
My initial report shows a pretty gruesome story for my beloved CouchDB. On every benchmark, Nebari, SQLite, and Sled all are measured on a different order of magnitude. For example:
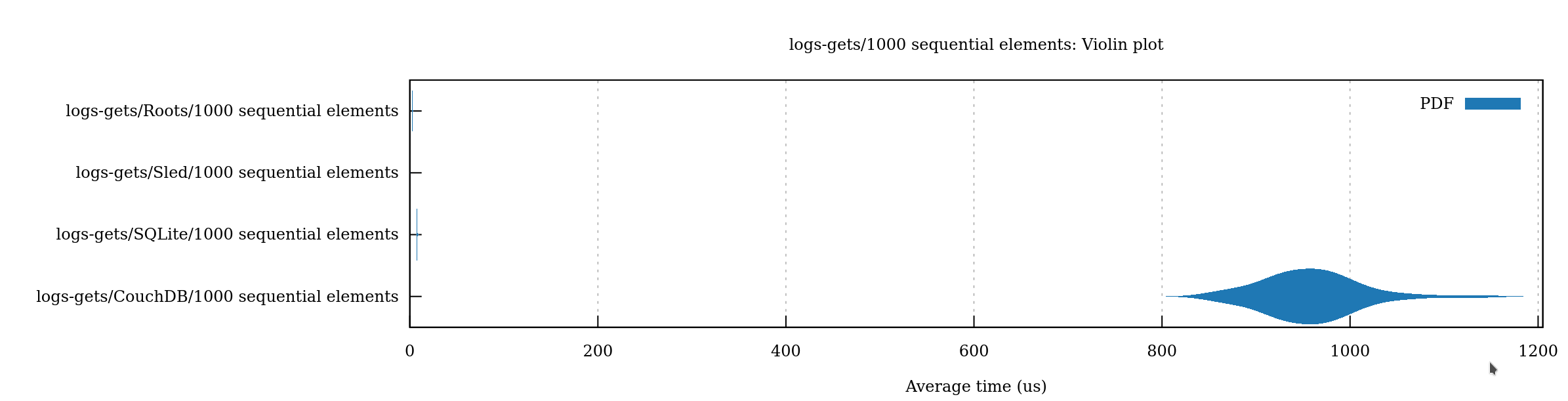
Sled is so fast that the line doesn’t even show up on the graph. Nebari is faster than SQLite in this particular benchmark, and then CouchDB is on its lonesome self at just shy of a full millisecond. What was the operation? Requesting a row by its primary key.
Was I happy now that I knew I was going to be able to beat CouchDB in performance? I should have been, but I knew I had a lot of performance left on the table.
I continued working on Nebari, flushing out its functionality, fixing its bugs, and eventually was able to hook up BonsaiDb atop of it. It was at that point that I discovered that Sled wasn’t the cause of the memory bug. If you read that post, you’ll see me conclude I’m going to keep writing Nebari for many reasons, but I didn’t name speed as one of them.
“I’m not a database engineer”
Imposter syndrome is a fun thing to fight. If you read through my posts about Nebari and BonsaiDb, you’ll see me asserting over and over: I’m not a database engineer. A month ago, I arguably wasn’t. But, I became one over the past month.
A great one? Probably not, but instead of being nervous about showing people Nebari, I’m now feeling proud to have written it. What changed my mind? It all came down to the realization that benchmarks are futile.
Every time I publish numbers, I make sure to reinforce something that everyone should already know: a benchmark suite is not a predictor of how your application will perform when built with the thing being benchmarked. You can pick the fastest libraries and still bring it to a crawl using an O(n^2) algorithm.
Yet, the true futility of benchmarking didn’t start hitting me until I decided I wanted to set up an automated way to run benchmarks on a machine that could produce reliable results over time. I was shocked at some of the initial results:

The top graph shows a dedicated Vultr VPS that might be a potential deployment target for us and the bottom graph shows results from results from my development machine. What’s interesting to see is that on my local machine, all engines insert a row in less than 40 microseconds, with the quickest being at around 16 microseconds (Sled).
Compare that with the VPS: The only engine that completes in less than 40us is Nebari at 35.7us. Sled is 3x slower in this particular benchmark, and SQLite is really not happy running on that VPS.
That moment was a turning point for me. If you click through the benchmarks at that stage as reported by my machine, you would most likely agree with me: I should be proud of what I pulled off in less than a month. But, if you then look at the benchmarks on the VPS, you see an even prettier picture for Nebari.
For those wondering why Nebari is faster in these situations, I can only hypothesize because I’m not that familiar with how storage works on a VPS host. My best guess is that appending to the end of a file is more optimized in these environments than whatever is needed for SQLite and Sled to update their databases (file locks? or just worse random write performance?).
I’m not trying to say that these benchmarks are useless. On the contrary, they’ve helped me understand where I’m likely leaving performance on the table and identify some low hanging fruit already. But, no matter how good I make any of these benchmarks perform, the actual performance in the hosted environment will likely be much different than what I can simulate on my own developer machine. At the end of the day, the only way to optimize the shipping application is going to be to profile the application itself.
The final nail in my imposter syndrome’s coffin came yesterday when I finished switching BonsaiDb over to Nebari’s transaction log. I measured the save_documents benchmark locally, and saw that my new implementation landed slightly slower than Sled (but with full revision history supported). I then realized I never looked at the performance of save_documents on a VPS before.
I dug through Github Actions logs to see the benchmark results. After looking for the lowest numbers across several old runs, here’s the fastest results compared:
BonsaiDb on Sled:
save_documents/1024 time: [388.02 us 395.56 us 403.93 us]
thrpt: [2.4177 MiB/s 2.4688 MiB/s 2.5168 MiB/s]
save_documents/2048 time: [510.57 us 523.38 us 535.91 us]
thrpt: [3.6445 MiB/s 3.7317 MiB/s 3.8254 MiB/s]
save_documents/8192 time: [578.55 us 588.99 us 599.17 us]
thrpt: [13.039 MiB/s 13.264 MiB/s 13.504 MiB/s]
BonsaiDb on Nebari:
save_documents/1024 time: [187.73 us 194.35 us 201.45 us]
thrpt: [4.8477 MiB/s 5.0247 MiB/s 5.2020 MiB/s]
save_documents/2048 time: [188.09 us 192.51 us 197.58 us]
thrpt: [9.8850 MiB/s 10.146 MiB/s 10.384 MiB/s]
save_documents/8192 time: [272.55 us 280.89 us 291.47 us]
thrpt: [26.804 MiB/s 27.813 MiB/s 28.664 MiB/s]
It may sound silly, but seeing these results was cathartic. For a month, I was doing my best to sound confident in what I was doing, but at the end of each day, I found myself fearing that I would ultimately fail to build something that could eventually support my visions of grandeur. I’m confident if I had a more exhaustive benchmark suite for BonsaiDb there would be no clear winner across all measurements.
But, for a project started a month ago to be in the same realm as SQLite and Sled? I’m very happy with that.
Unveiling the hosted benchmark suite
I moved on to finishing up a nice hosted overview of benchmarks, which also describes what each benchmark is testing a little better than the Criterion reports do. These benchmarks are run on an instance that we’ve identified as a potential deployment target for Cosmic Verge, although it’s still too early to know exactly what environment we’ll ultimately call home.
Despite the title of this post, benchmarks are still going to be a critical part of developing BonsaiDb and Nebari. It’s just important to remember that benchmarks will always be limited in what they can tell you, unless the benchmark is specifically written for your particular use case and being run in exactly the same environment as your production environment.
Nebari is shaping up into a neat library on its own, but I’m excited to start putting more time back into BonsaiDb and Gooey.